Graphs¶
A graph is a pair \((V, E)\) where \(V\) is the set of vertices (nodes) and \(E \subseteq V \times V\) is the set of edges (i.e. pairs \((u, v)\) where \(u, v \in V\)).
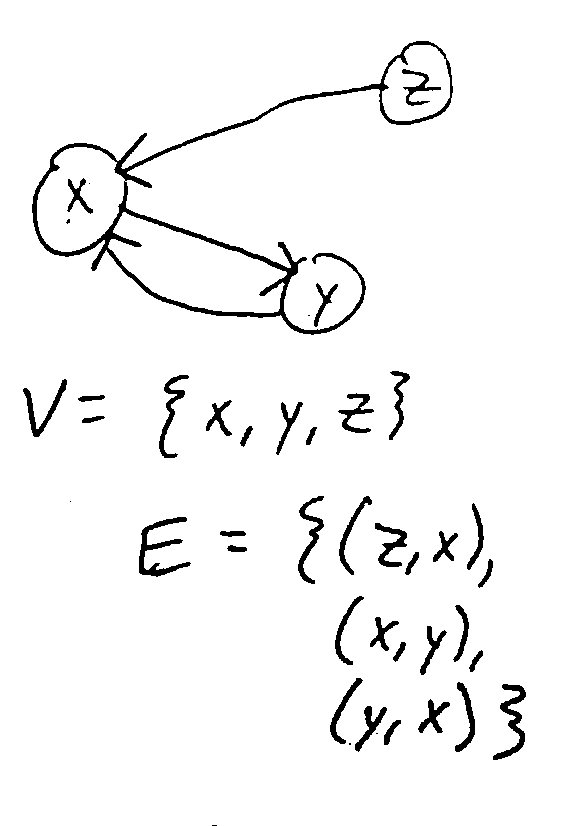
Note
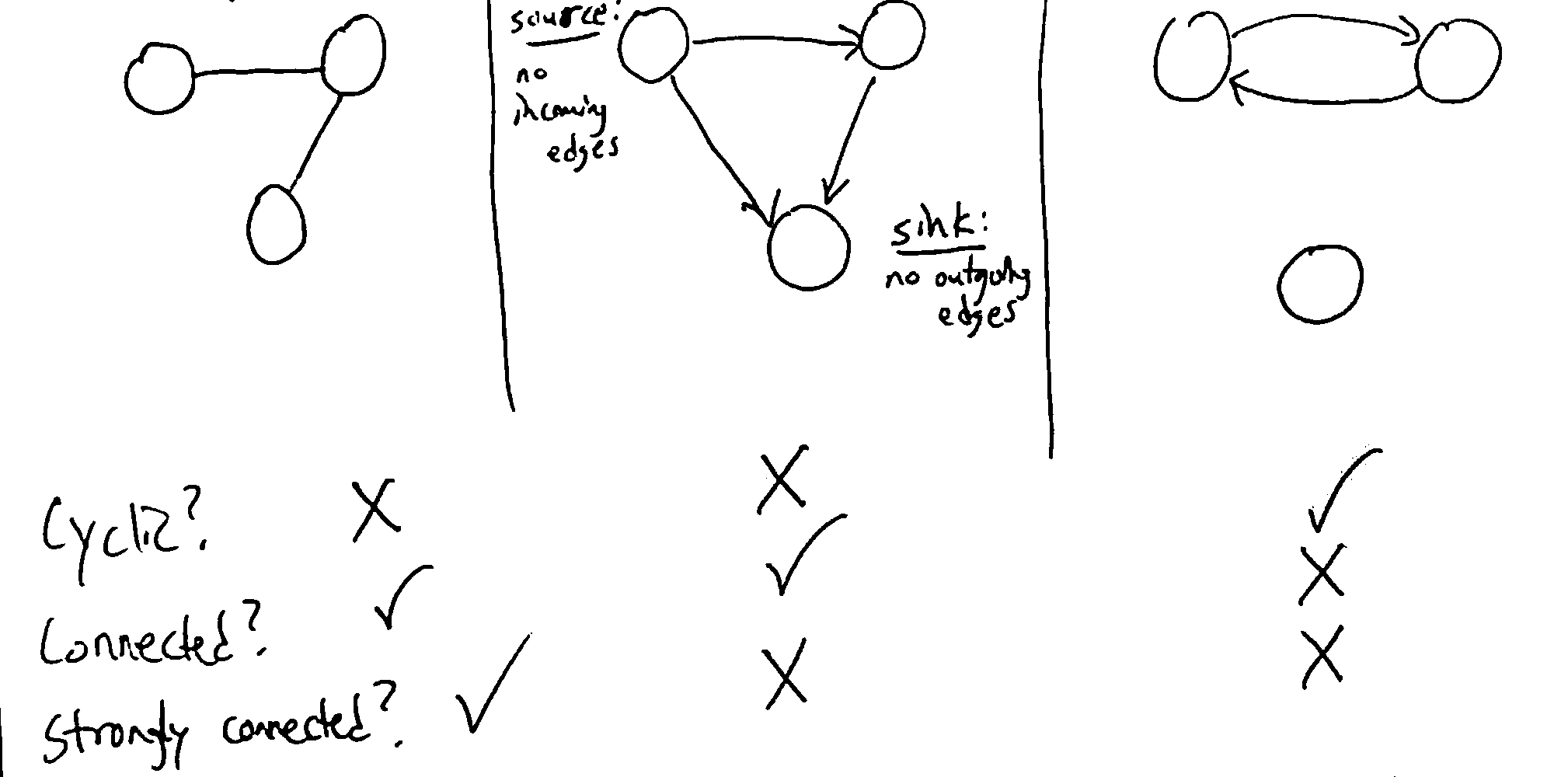
The image above is a directed graph (digraph), where the direction of the nodes matter. In an undirected graph, the direction doesn’t matter, so \(\forall u,v \in V, (u, v) \in E \iff (v, u) \in E\).
For a vertex \(v \in V\), its outdegree is the number of edges going out from it, and its indegree is the number of edges going into it.
In an undirected graph, this is simplified to degree: the number of edges connected to an edge.
A path in a graph \(G = (V, E)\) is a sequence of vertices \(v_1, v_2,... ,v_k \in V\) where for all \(i < k, (v_i, v_{i+1}) \in E\) (i.e. there is an edge from each vertex in the path to the next).
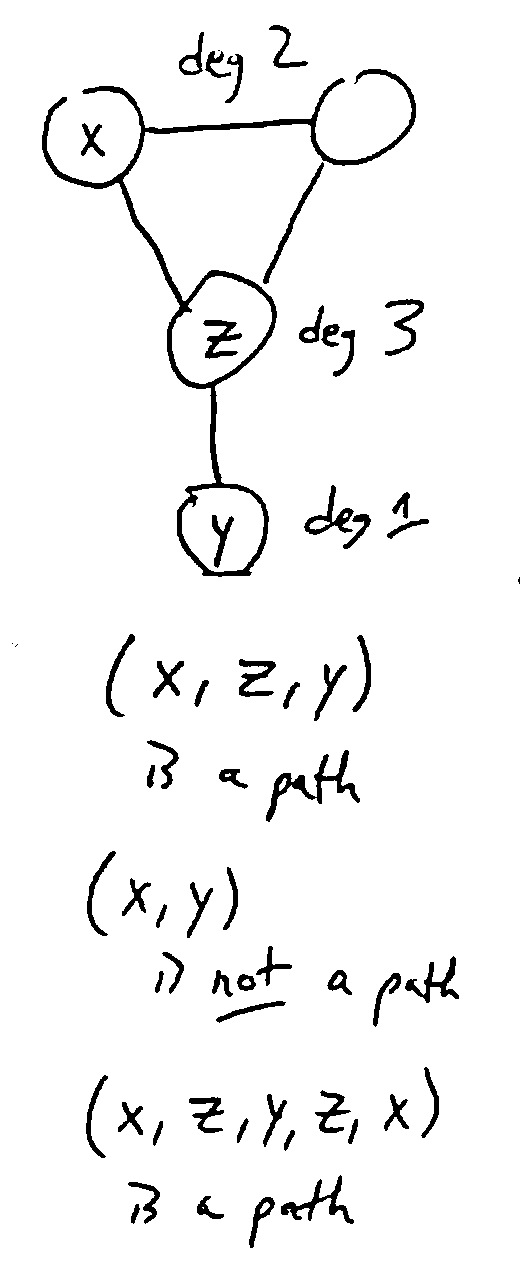
A path is simple if it contains no repeated vertices.
A cycle is a nontrivial path starting and ending at the same vertex. A graph is cyclic if it contains a cycle, or acyclic if not.
Note
For a digraph, nontrivial means a path of at least 2 nodes. For an undirected graph, it’s at least 3 (cannot use the same edge to go back and forth)
Ex. This digraph is acyclic: \((x, y, z, w, x)\) is not a path, since there is no path from w to x.
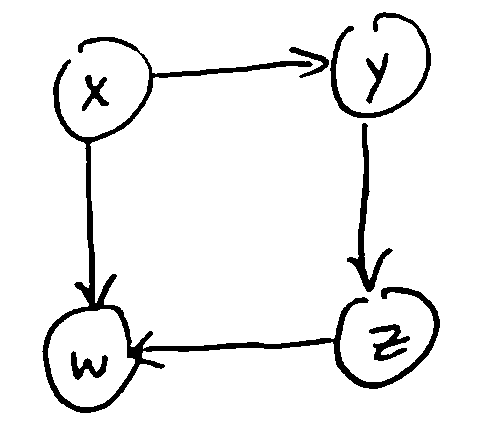
Some more examples:
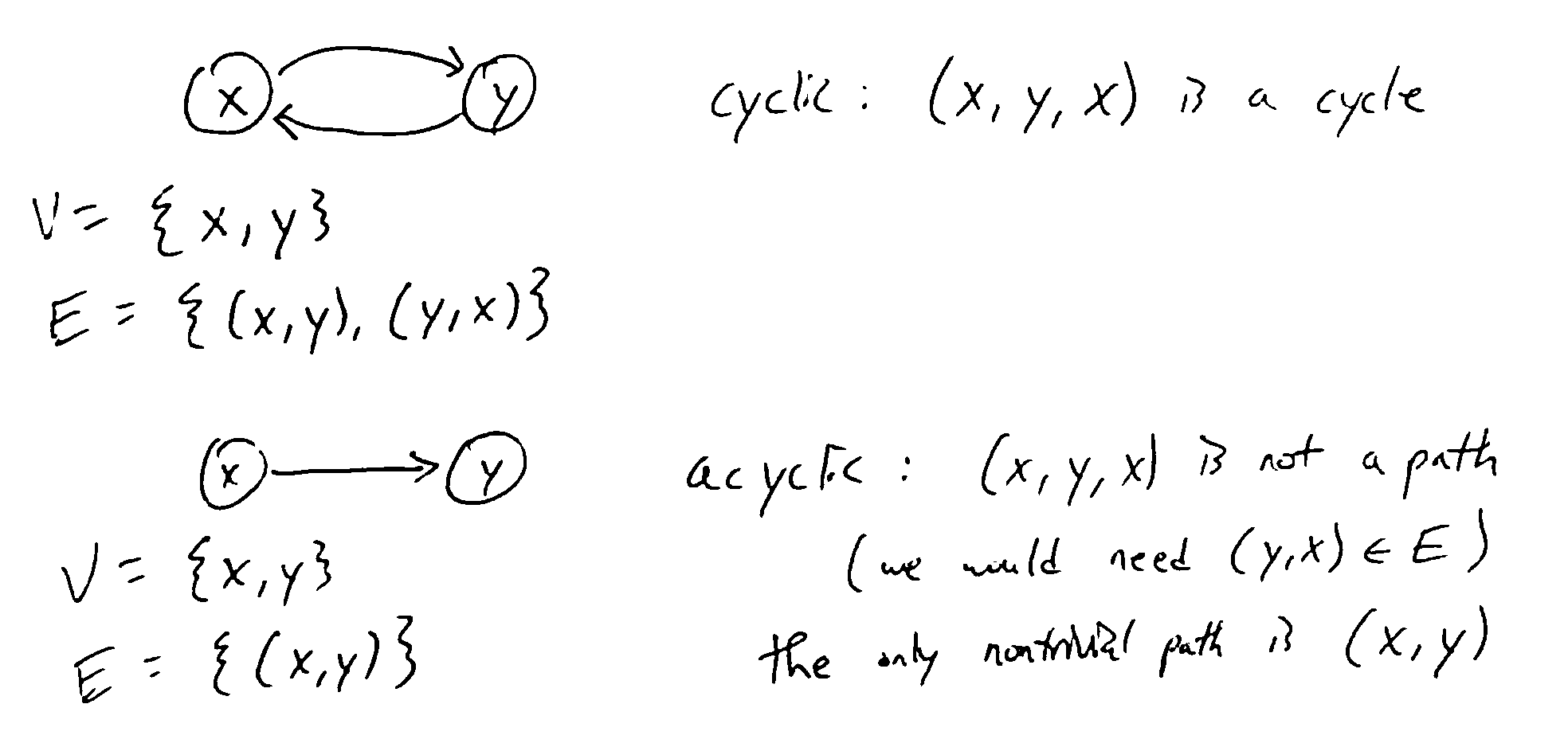
A graph is connected if \(\forall u, v \in V\), there is a path from u to v or vice versa.
A digraph is strongly connected if \(\forall u, v \in V\), there is a path from u to v. (For undirected graphs, connected = strongly connected.)
Note
For a directed graph mith more than one vertex, being strongly connected implies that the graph is cyclic, since a path from u to v and vice versa exists.
Algorithms¶
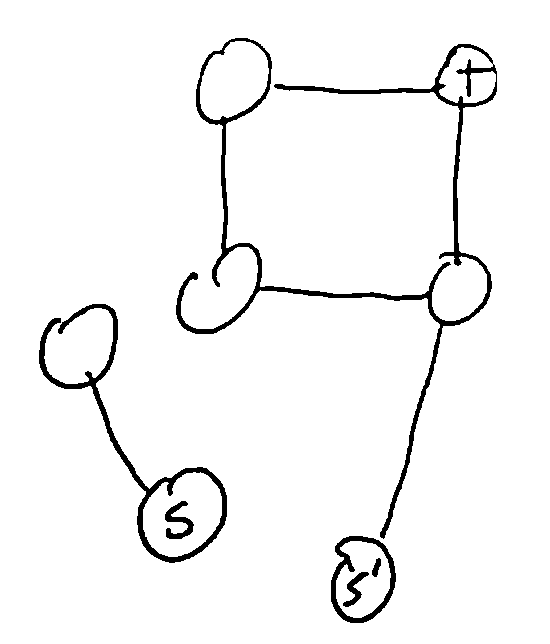
S-T Connectivity Problem¶
Given vertices \(s, t \in V\), is there a path from s to t? (Later: what’s the shortest such path?)
BFS¶
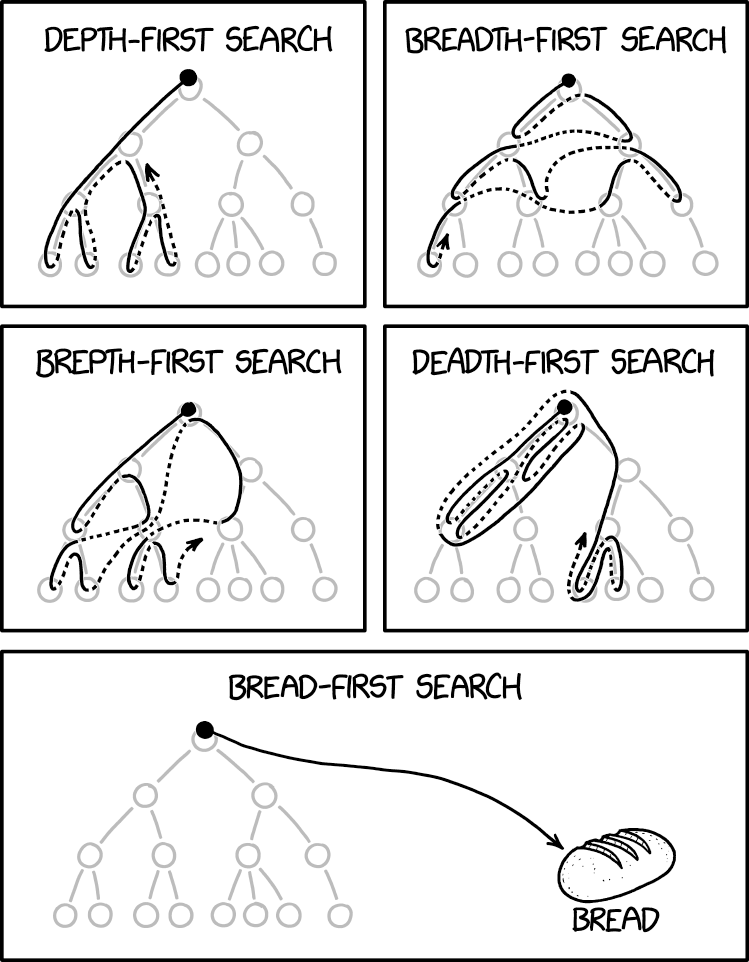
Traverse graph starting from a given vertex, processing vertices in the order they can be reached. Only visit each vertex once, keeping track of the set of already visited vertices. Often implemented using a FIFO queue.
The traversal can be visualized as a tree, where we visit nodes in top-down, left-right order.
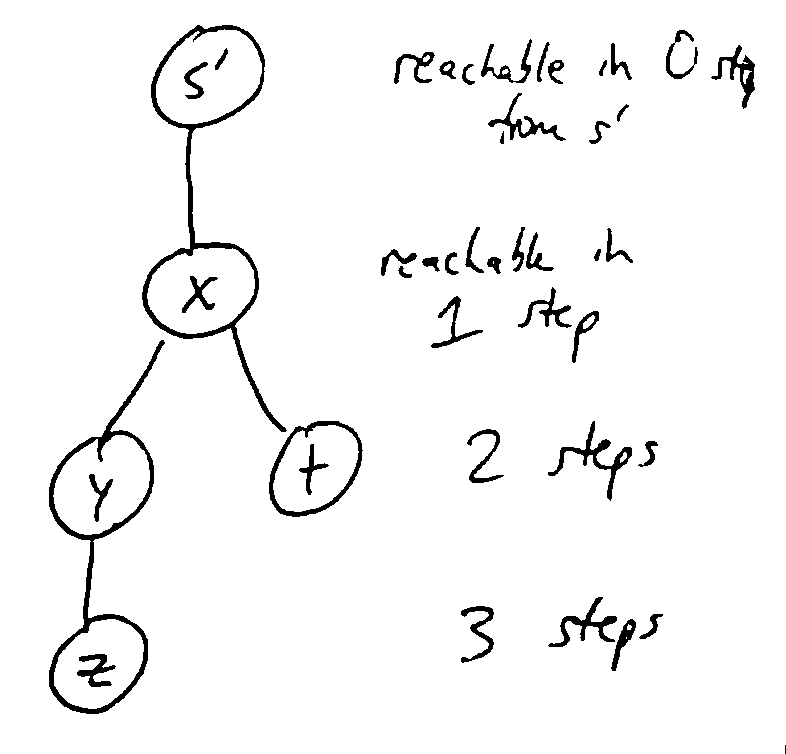
BFS(v):
Initialize a FIFO queue with a single item v
Initialize a set of seen vertices with a single item v
while the queue is not empty:
u = pop the next element in the queue
Visit vertex u
for each edge (u, w):
if w is not already seen:
add it to the queue
add it to set of seen vertices
Note
When we first add a vertex to the queue, we mark it as seen, so it can’t be added to the queue again. Since there are only finitely-many vertices, BFS will eventually terminate.
Each edge gets checked at most once (in each direction), so if there are n vertices and m edges, the runtime is \(\Theta(n+m)\) (assuming you can get the edges out from a vertices in constant time).
DFS¶
Traverse like BFS, except recursively visit all descendants of a vertex before moving on to the next one (at the same depth). This can be implemented without a queue, only using the call stack.
DFS(v):
mark v as visited
for each edge (v, u):
if u is not visited, DFS(u)
Note
As with DFS, we visit each vertex at most once, and process each edge at most once in each direction, so runtime is \(\Theta(n+m)\).
We call \(\Theta(n+m)\) linear time for graphs with n vertices and m edges.
Representing Graphs¶
- Adjacency lists: for each vertex, have a list of outgoing edges
Allows for linear iteration over all edges from a vertex
Checking if a particular edge exists is expensive
Size for n vertices, m edges = \(\Theta(n + m)\)
- Adjancency matrix: a matrix with entry \((i, j)\) indicating an edge from i to j
Constant time to check if a particular edge exists
but the size based on number of vertices is \(\Theta(n^2)\)
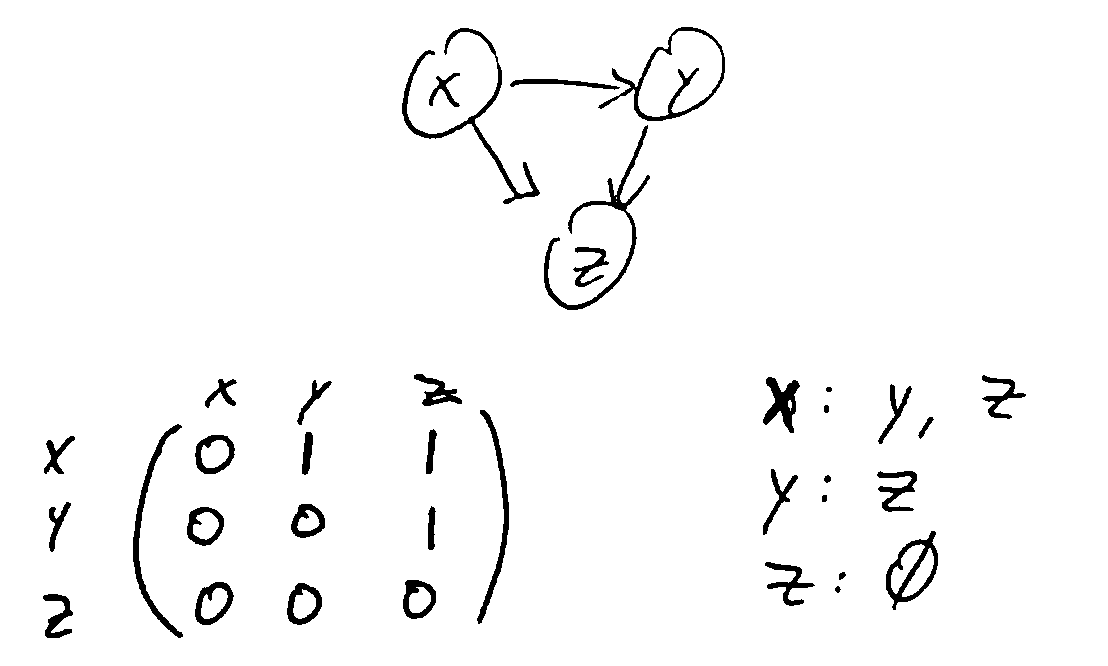
A graph with n vertices has \(\leq {n \choose 2}\) edges if undirected, or \(\leq n^2\) if directed and we allow self-loops (or \(\leq n(n-1)\) if no self loops).
In all cases, \(m=O(n^2)\). This makes the size of an adjacency list \(O(n^2)\).
If we really have a ton of edges, the two representations are the same; but if you have a sparse graph (\(m << n^2\)), then the adjacency list is more memory-efficient.
This means that a \(\Theta(n^2)\) algorithm can run in linear time (\(\Theta(n+m)\)) on dense graphs because \(m = \Theta(n^2)\).
So \(\Theta(n^2)\) is optimal for dense graphs, but not for sparse graphs.
More Problems¶
Cyclic Test¶
testing if a graph is cyclic
use DFS to traverse, keep track of vertices visited along the way
if we find an edge back to any such vertex, we have a cycle
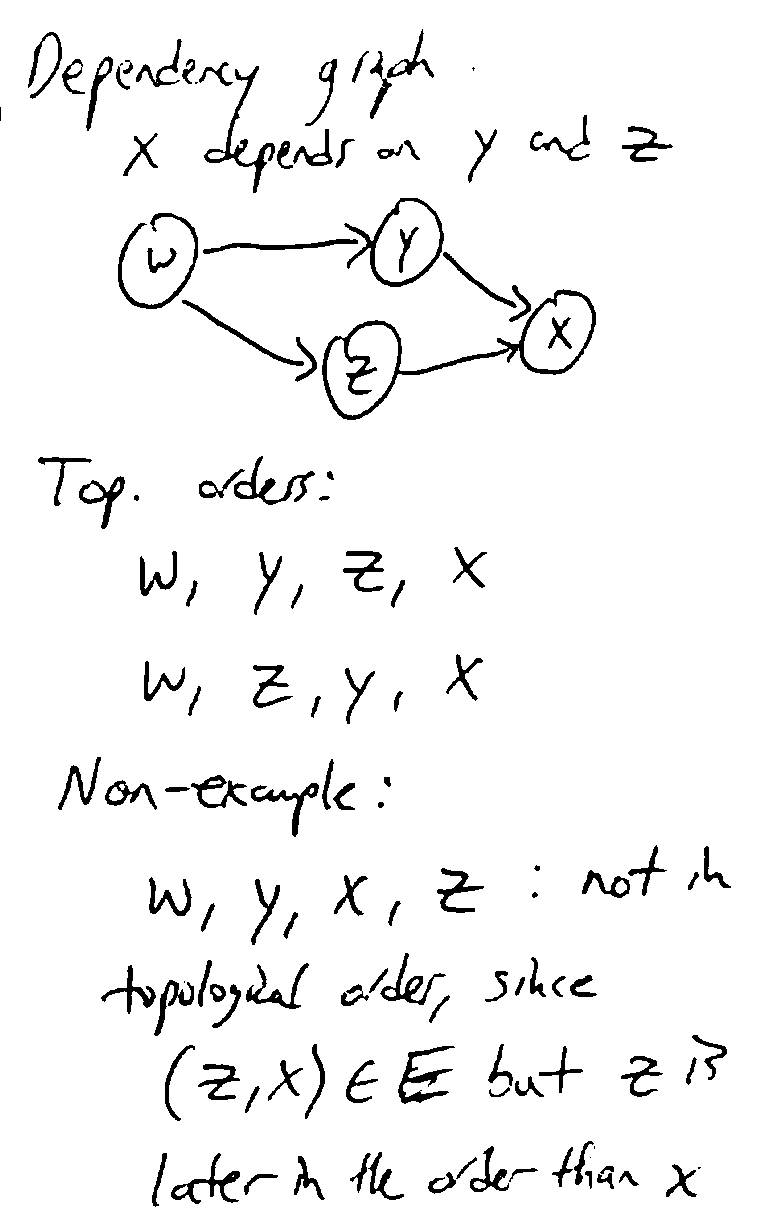
Topological Order¶
- Finding a topological ordering of a DAG (directed acyclic graph)
an ordering \(v_1, v_2, v_n\) of the vertices such that if \((v_i, v_j) \in E\), then \(i < j\)
- we can find topological order using postorder traversal in DFS
after DFS has visited all descendants of a vertex, prepend the vertex to the topological order
make sure to iterate all connected components of the graph, not just one
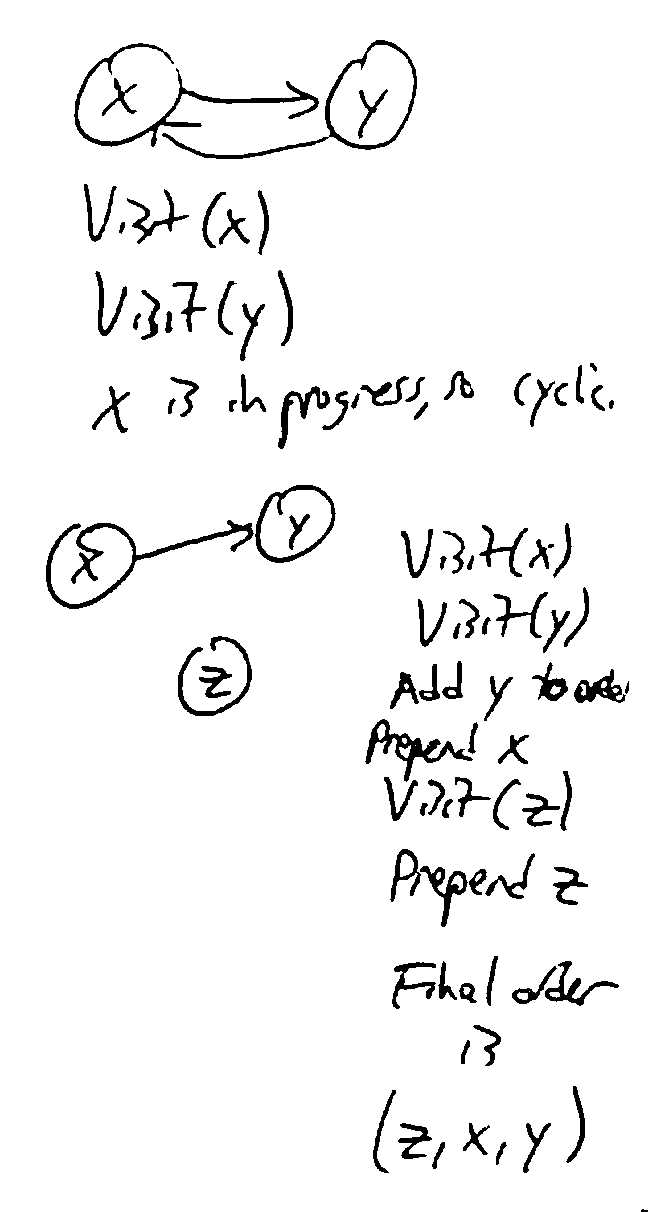
def Topo-Sort(G):
for v in V:
if v is not visited:
Visit(v)
def Visit(v):
mark v as visited
mark v as in progress // temporarily
for edges (v, u) in E:
if u is in progress, G is cyclic // there is no topological order
if u is not visited:
Visit(u)
mark v as not in progress
prepend v to the topological order
Minimum Spanning Tree¶
Suppose you need to wire all houses in a town together (represented as a graph, and the edges represent where power lines can be built), Build a power line to use the minimal amount of wire.
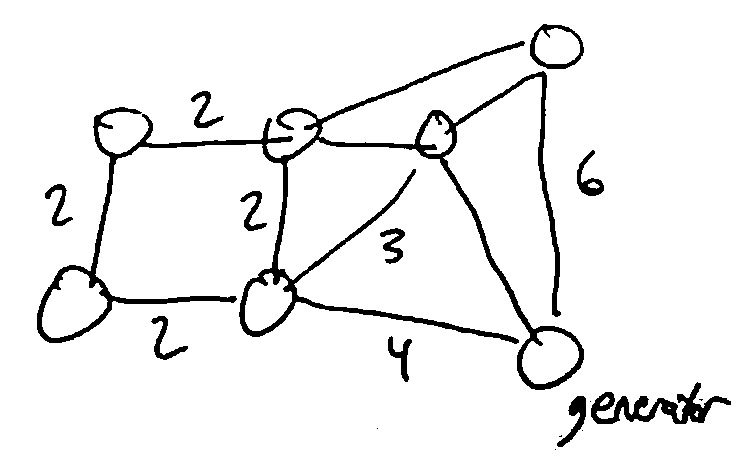
Given a weighted graph, (i.e. each edge has a numerical weight), we want to find a minimum spanning tree: a selection of edges of G that connects every vertex, is a tree (any cycles are unnecessary), and has least total weight.
Kruskal’s Algorithm¶
Main idea: add edges to the tree 1 at a time, in order from least weight to largest weight, skipping edges that would create a cycle
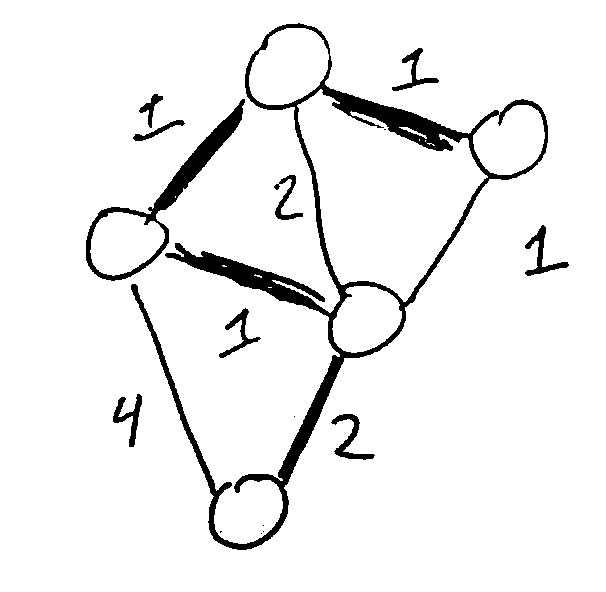
This is an example of a greedy algorithm, since it picks the best available option at each step.
We use a disjoint-set forest to keep track of sets of connected components.
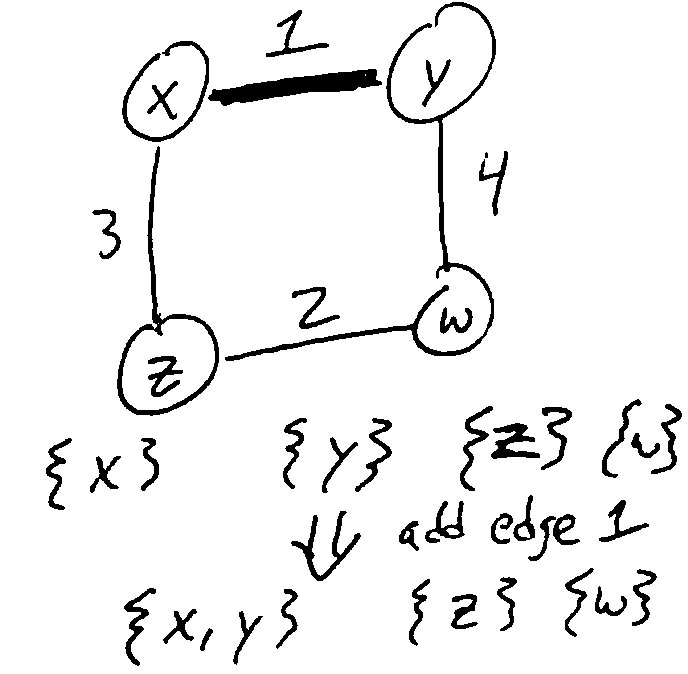
Initially, all vertices are in their own sets. When we add an edge, we Union the sets of its two vertices together. If we would add an edge that would connect two vertices in the same set, we skip it (it would cause a cycle).
1 2 3 4 5 6 7 8 | def Kruskal(G, weights w):
initialize a disjoint-set forest on V
sort E in order of increasing w(e)
while all vertices are not connected: // i.e. until n-1 edges are added
take the next edge from E, (u, v)
if Find(u) != Find(v):
add (u, v) to the tree
Union(u, v)
|
Runtime:
L2: \(\Theta(n)\)
L3: \(\Theta(m \log m)\)
- L4: \(m\) iterations of the loop worst case
Note that this lets us use the amortized runtime of Find and Union
L6: two finds (\(\Theta(\alpha(n))\) each)
L8: and a union (\(\Theta(\alpha(n))\))
Note that \(m \alpha(n) < m \log m\) since \(n \leq m\)
So the total runtime is \(\Theta(m \log m) = \Theta(m \log n)\) (since \(m = \Omega(n)\) since G is connected).
This assumes G is represented by an adjacency list, so that we can construct the list E in \(\Theta(m)\) time.
Prim’s Algorithm¶
Main idea: build the tree one vertex at a time, always picking the cheapest vertex
Need to maintain a set of vertices S which have already been connected to the root; also need to maintain the cost of all vertices which could be added next (the “frontier”).
Use a priority queue to store these costs: the key of vertex \(v \notin S\) will be \(\min w((u, v) \in E), u \in S\)
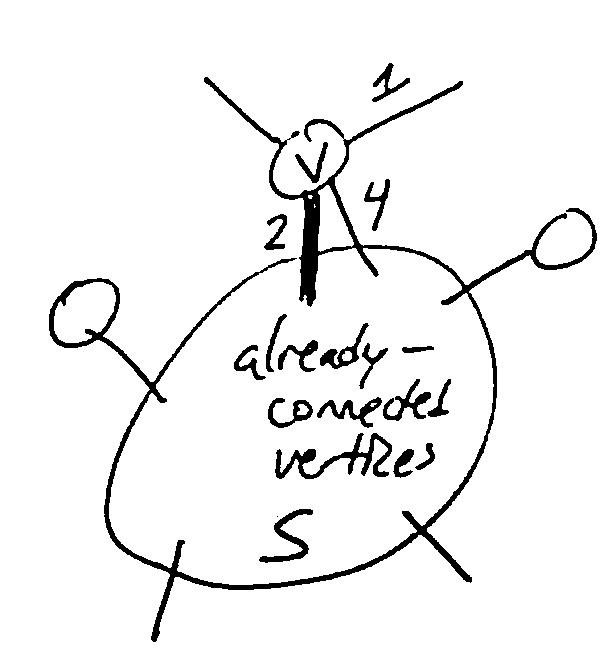
After selecting a vertex v of least cost and adding it to S, some vertices may now be reachable via cheaper edges, so we need to decrease their keys in the queue.
1 2 3 4 5 6 7 8 9 10 | def Prim(G, weights w, root r):
initialize a PQ Q with items V // all keys are infinity except r = 0
initialize an array T[v] to None for all vertices v in V
while Q is not empty:
v = Delete-Min(Q) // assume delete returns the deleted elem
for each edge (v, u):
if u is in Q and w(v, u) < Key(u):
Decrease-Key(Q, u, w(v, u))
T[u] = (v, u) // keep track of the edge used to reach u
return T
|
Runtime:
n iterations of the main loop (1 per vertex), with 1 Delete-Min per iteration
every edge considered at most once in each direction, so at most m Decrease-Key
we use a Fibonacci heap, (Delete-Min = \(\Theta(\log n)\), Decrease-Key = \(\Theta(1)\) amortized)
so the total runtime is \(\Theta(m + n \log n)\).
Note
We can compare the runtime of these two algorithms on sparse and dense graphs:
On a sparse graph, i.e. \(m = \Theta(n)\), the two have the same runtime: \(\Theta(n \log n)\).
On a dense graph, i.e. \(m = \Theta(n^2)\), Kruskal’s ends up with \(\Theta(n^2 \log n)\) and Prim’s with \(\Theta(n^2)\).
Proofs¶
Need to prove that the greedy choices (picking the cheapest edge at each step) leads to an overall optimal tree.
Key technique: loop invariants: A property P that:
is true at the beginning of the loop
is preserved by one iteration of the loop (i.e. if P is true at the start of the loop, it is true at the end)
By induction on the number of iterations, a loop invariant will be true when the loop terminates. For our MST algorithms, our invariant will be: The set of edges added to the tree so far is a subset of some MST.
If we can show that this is an invariant, then since the tree we finally return connects all vertices, it must be a MST.
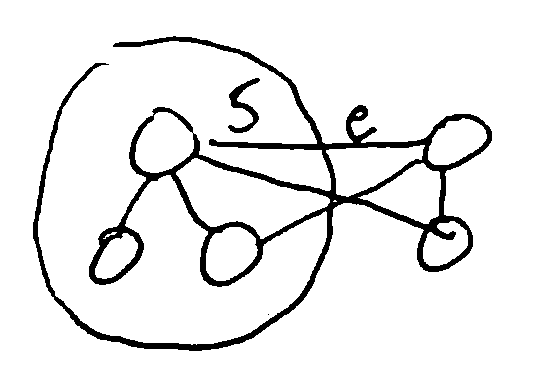
Lemma (cut property): Let \(G=(V,E)\) be a connected undirected graph where all edges have distinct weights. For any \(S\subseteq V\), if \(e \in E\) is the cheapest edge from \(S\) to \(V-S\), every MST of \(G\) contains \(e\).
Kruskal’s¶
Thm: Kruskal’s alg is correct.
Pf: We’ll establish the loop invariant above.
Base case: before adding any edges, the edges added so far is \(\emptyset\), which is a subset of some MST.
Inductive case: suppose the edges added so far are contained in an MST \(T\), and we’re about to add the edge \((u, v)\).
Let \(S\) be all vertices already connected to \(u\).
Since Kruskal’s doesn’t add edges between already connected vertices, \(v \notin S\)
Then \((u, v)\) must be the cheapest edge from \(S\) to \(V-S\), since otherwise a cheaper edge would have been added earlier in the algorithm, and then \(v \in S\)
Then by the cut property, every MST of \(G\) contains \((u, v)\)
In particular, \(T\) contains \((u, v)\), so the set of edges added up to and including \((u, v)\) is also contained in \(T\), which is a MST
So the loop invariant is actually an invariant, and by induction it holds at the end of the algorithm
So all edges added are in an MST, and since they are a spanning tree, they are a MST. Since the algorithm doesn’t terminate until we have a spanning tree, the returned tree must be a MST.
Prim’s¶
Idea: Let \(S\) be the set of all vertices connected so far. Prim’s then adds the cheapest edge from \(S\) to \(V - S\).
So by the cut property, the newly added edge is part of every MST. The proof follows as above.
Cut Property¶
Proof of the following lemma, restated from above:
Let \(G=(V,E)\) be a connected undirected graph where all edges have distinct weights. For any \(S\subseteq V\), if \(e \in E\) is the cheapest edge from \(S\) to \(V-S\), every MST of \(G\) contains \(e\).
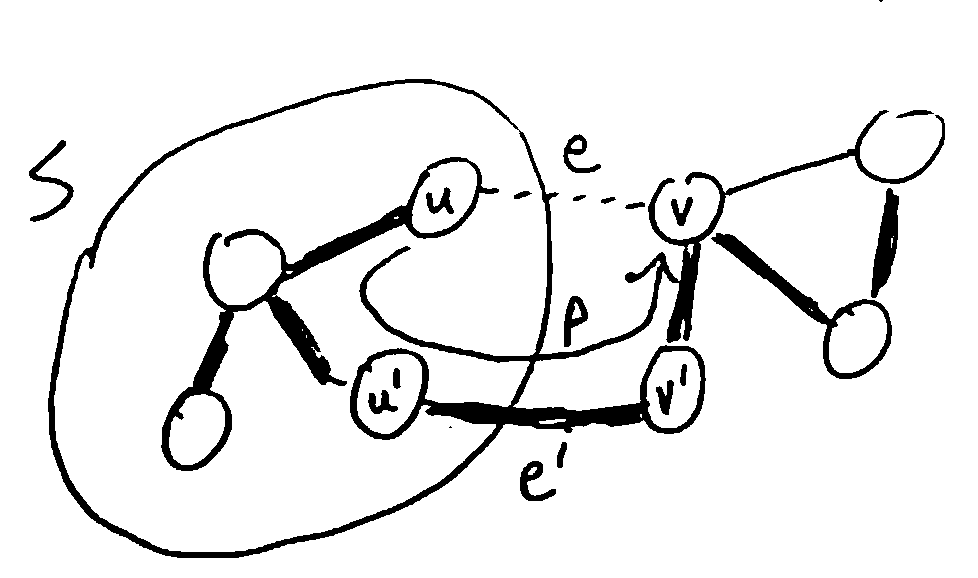
Suppose there was some MST \(T\) which doesn’t contain \(e=(u, v)\). Since \(T\) is a spanning tree, it contains a path \(P = (u, ..., v)\). Since \(u \in S\) and \(v \notin S\), \(P\) contains some edge \(e' = (u', v')\) with \(u' \in S, v' \notin S\). We claim that exchanging \(e\) for \(e'\) will give a spanning tree \(T'\) of lower weight than \(T\), which contradicts \(T\) being an MST.
First, \(T'\) has smaller weight than \(T\), since \(e\) is cheaper than \(e'\) by definition.
Next, \(T'\) connects all vertices, since \(T\) does, and any path that went through \(e'\) can be rerouted to use \(e\) instead: follow \(P\) backwards from \(u'\) to \(u\), take \(e\) from:math:u to \(v\), then follow \(P\) backwards from \(v\) to \(v'\), and then continue the old path normally. (e.g. \((a, ..., u', v', ..., b) \to (a, ..., u', ..., u, v, ..., v', ..., b)\))
Finally, \(T'\) is also acyclic, since adding \(e\) to \(T\) produces a single cycle, which is then broken by removing \(e'\).
So \(T'\) is a spanning tree of lower weight than \(T\) - contradiction! Therefore every MST of G must contain the edge e.
Note
To relax the assumption of distinct edge weights, imagine adding tiny extra weights to break any ties in the MST algorithm; if the changes in the weights are sufficiently small, then any MST of the new graph is also an MST of the original (see hw4).
Single-Source Shortest Paths¶
Given a directed graph with nonnegative edge weights (lengths) and a start vertex \(s\), find the shortest paths from \(s\) to every other vertex (shortest = minimum total length/weight). (Assume every vertex is reachable from s.)
To represent the shortest paths, we use a shortest-path tree: each vertex stores the edge that should be used to reach it from s along the shortest path.
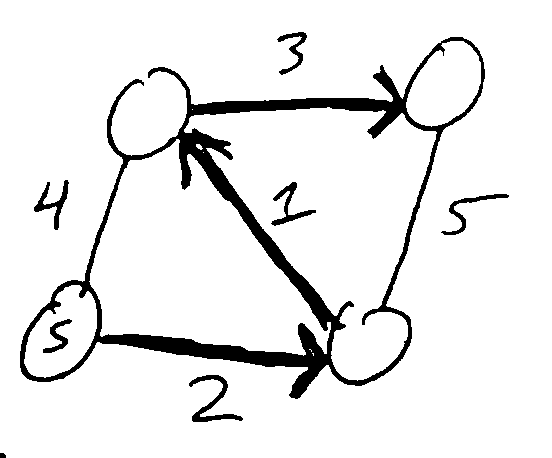
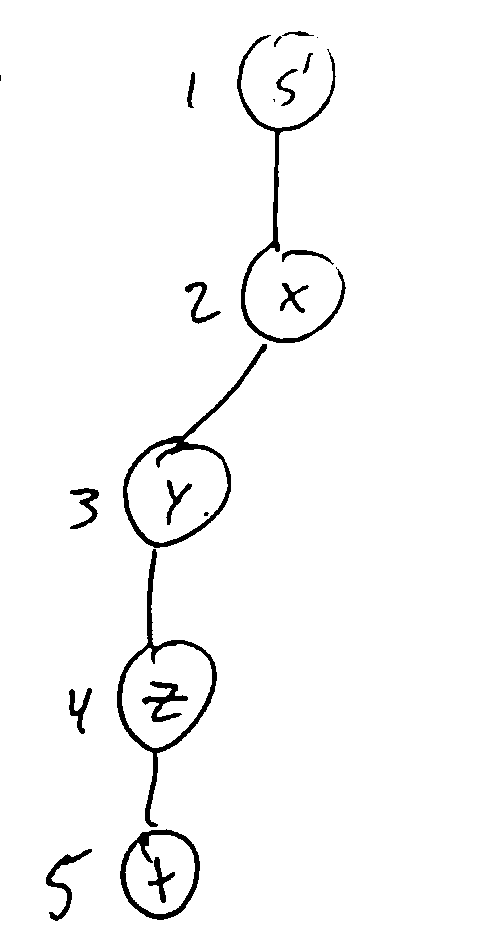
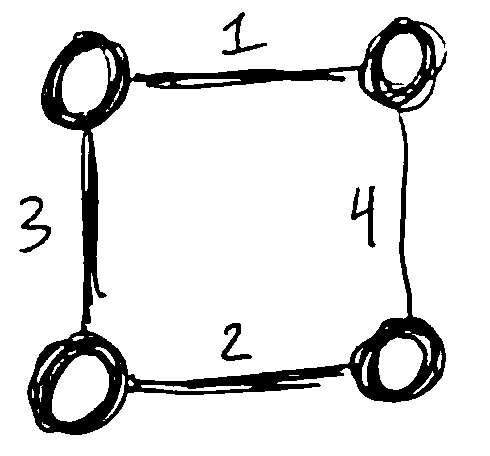
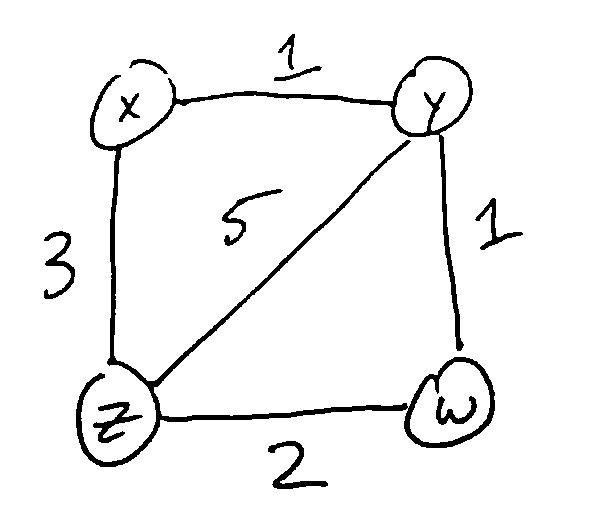
Ex. For this graph, starting from vertex z, the shortest-path tree T is:
T[x] = (z, x)
T[y] = (w, y)
T[w] = (z, w)
Dijkstra’s Algorithm¶
Greedy algorithm for building the shortest-path tree. Very similar to Prim’s, but the cost of a vertex is the length of the shortest known path to reach it from s
Idea: Maintain a set of vertices S already added to the shortest-path tree; for these vertices, we know their distance d(v) from s. At each step, add a vertex \(v \notin S\) which minimizes \(d(u) + w(u, v)\) over all \(u \in S\) with \((u, v) \in E\)
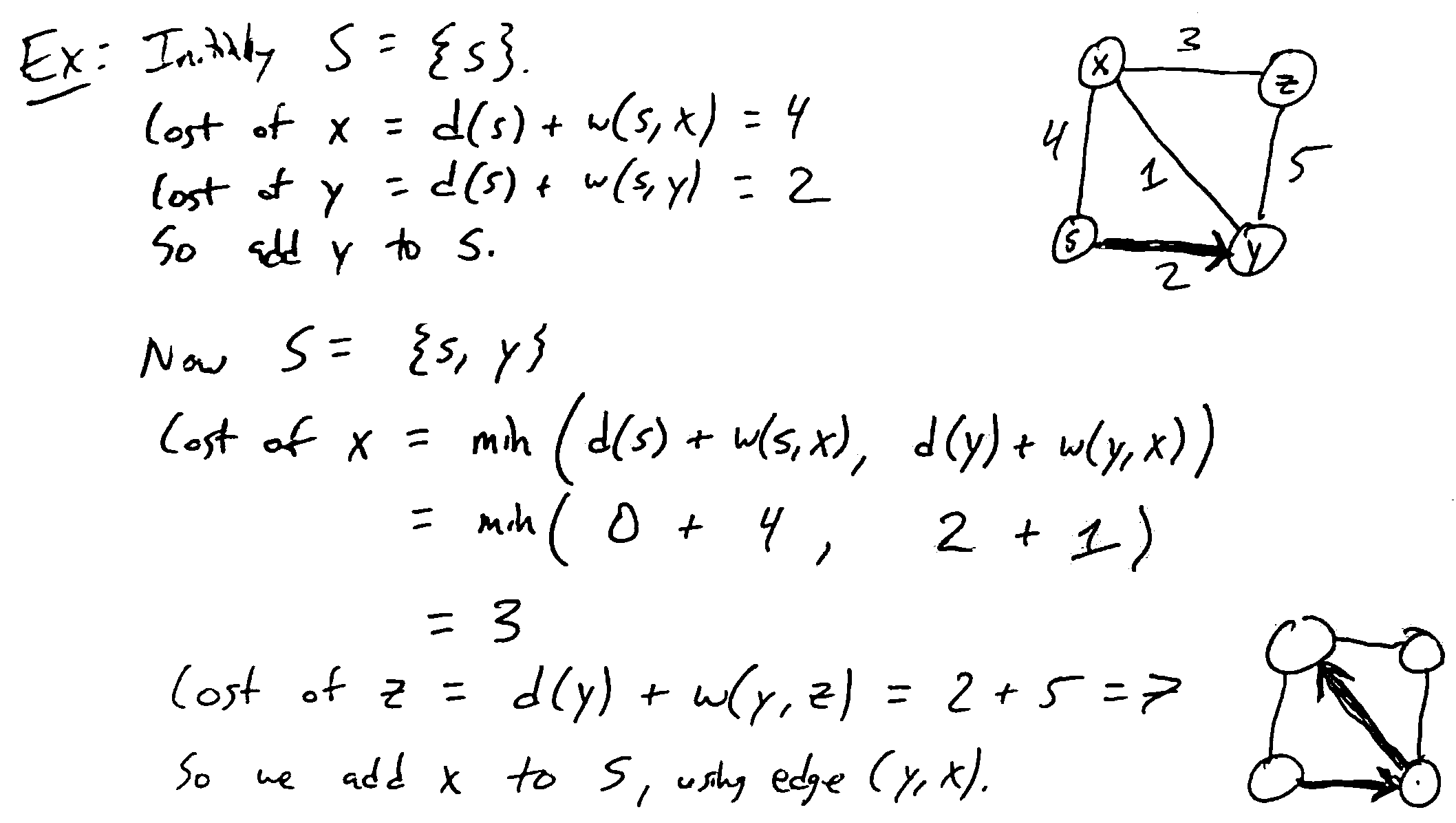
1 2 3 4 5 6 7 8 9 10 | def Dijkstra(G, weights w, source s in V):
Initialize a PQ Q with items V; all keys d(v) = inf except d(s) = 0
Initialize an array T[v] to None for all v in V
while Q is not empty:
u = Delete-Min(Q)
for each edge (u, v) in E:
if v in Q and d(v) > d(u) + w(u, v):
Decrease-Key(Q, v, d(u) + w(u, v))
T[v] = u
return T
|
Runtime: Same as Prim’s algorithm - \(\Theta(m + n \log n)\) using a Fibonacci heap
Proof¶
To prove correctness, we’ll use the following loop invariant I:
for all vertices v popped off the queue so far:
\(d(v)\) is the distance from s to v and
- there is a path \(P_v\) from s to v in T which is a shortest path
\(P_v=(v, T[v], T[T[v]], ..., s)\) reversed
To show I is an invariant, need to prove it is true initially and it preserved by one iteration. If S is the set of popped-off vertices, then initially \(S = \emptyset\) so I holds vacuously.
Suppose I holds at the beginning of an iteration. If we pop vertex v, and \(T[v]=(u, v)\), then \(u \in S\), so \(P_u\) is a shortest path from s to u and \(d(u)\) is the distance from s to u. Also \(d(v) = d(u) + w(u, v)\) by line 8, which is the length of the path \(P_v\).
Now suppose there were a shorter path P from s to v. Since \(v \notin S\), P must leave S at some point: let the first edge leaving S be \((x, y)\). Since \(x \in S\), we previously considered the edge \((x, y)\) and therefore \(d(y) \leq d(x) + w(x, y)\). Also, since \(y \notin S\), the algorithm selected v to pop before y, so \(d(v) \leq d(y)\). Then \(d(v) \leq d(x) + w(x, y)\) but the length of P is \(d(x) + w(x, y)\), and \(P_v\) has length \(d(v)\), so P cannot be shorter than \(P_v\). This is a contradiction, so \(P_v\) is in fact a shortest path from s to v.
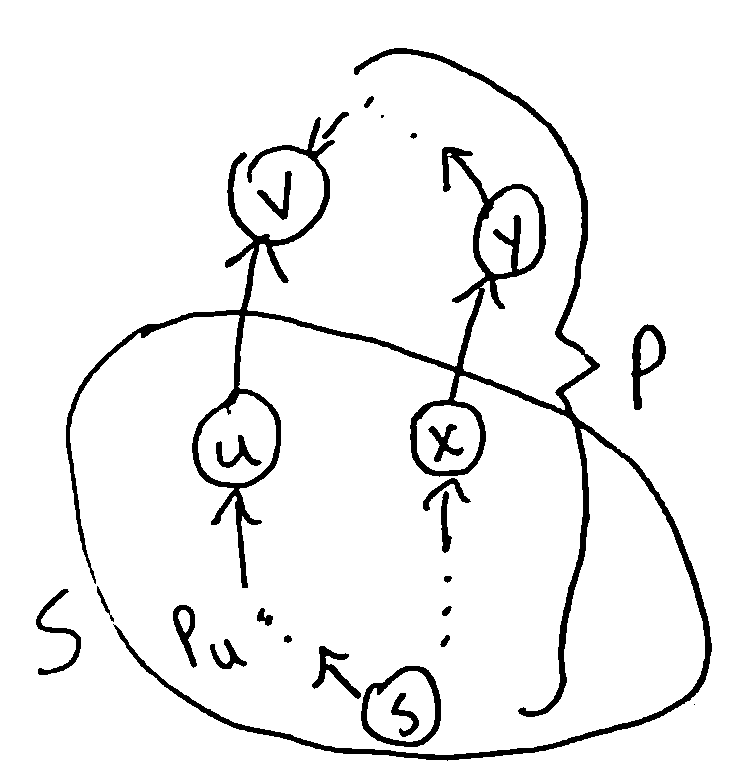
Then \(d(v)\) is the distance from s to v, so I holds after the end of the loop. Therefore I is an invariant, and by induction it holds when the algorithm terminates. Since all vertices are popped off when the algorithm terminates, T must then be a shortest path’s tree (and \(d(v)\) is the distance from s to v for all v)