Greedy Algorithms¶
Idea: build up a solution incrementally, taking the best available option at each step (e.g. Kruskal/Prim)
This kind of “local” reasoning doesn’t necessarily yield a globally optimal solution. The trick in designing a greedy algorithm is to find a greedy strategy that you can prove gives a global optimum.
Interval Scheduling Problem¶
Have a resource which can only be used by one person at a time, and people want to use it at different time periods.
We have n requests of the form \((s(i), f(i))\) giving the starting and finishing times. Want to find the largest possible subset (by cardinality) of non-overlapping (compatible) requests.
Natural greedy approach:
Use some heuristic to select a request i and add it to our set
Delete all requests incompatible with i
Repeat until there are no requests left
Possible heuristics:
Earliest request (does not work)
Shortest request (does not work)
Fewest conflicts (does not work)
- Request finishing first (works!)
Intuition: maximize the time remaining in which to service other requests
Optimality¶
How do you prove optimality of a greedy strategy?
Exchange Argument¶
Take an optimal solution and transform it into the solution that the algorithm outputs without increasing its cost.
e.g. proof of cut property: we took an MST and showed that using the edge chosen by Kruskal/Prim would decrease its cost
Inductive Argument¶
Break up an optimal solution into stages, and show inductively that the greedy algorithm does at least as well as the optimal solution in each successive stage
ISP¶
We use the inductive argument to prove the optimality of the “smallest finishing time” heuristic for the interval scheduling problem:
Call the set of intervals chosen by the algorithm A.
First, A is compatible, since we throw out incompatible requests each time we add a new request to A.
Take an optimal set of requests O. Need to show that \(|A| = |O|\).
Let \(i_1, i_2, ..., i_k\) be the intervals of A in the order they were added.
Let \(j_1, j_2, ..., j_m\) be the intervals of O in left-to-right order.
Then need to show that \(k=m\). Intuition for our heuristic was to make the resource available as soon as possible, so let’s prove that (i.e., for all \(r \leq k, f(i_r) \leq f(j_r)\)). Prove by induction on r.
Base Case: \(r=1\) - Algorithm picks \(i_1\) to be the request with smallest finishing time, so \(f(i_1)\leq f(j_1)\).
Inductive Case: \(r > 1\) - Assume that \(f(i_{r-1}) \leq f(j_{r-1})\). Since \(j_{r-1}\) is compatible with \(j_r\), \(f(j_{r-1}) \leq s(j_r)\).
So by the hypothesis, \(f(i_{r-1}) \leq f(j_{r-1}) \leq s(j_r)\), so \(i_{r-1}\) is compatible with \(j_r\), and therefore \(j_r\) is one of the options considered when picking \(i_r\).
Since the algorithm picks the request with least finishing time amongst those consistent with the previously-chosen requests, \(f(i_r) \leq f(j_r)\).
So by induction, \(f(i_r) \leq f(j_r) \forall r \leq k\).
Now suppose that A was not optimal, i.e. \(k < m\). By above, \(f(i_k) \leq f(j_k)\). Since O is compatible, \(f(j_k) \leq s(j_{k+1})\), so \(j_{k+1}\) is compatible with \(i_k\), and the algorithm should not have terminated after \(i_k\) - contradiction.
Scheduling to Minimize Lateness¶
Have n jobs which have durations \(t_i\) and deadlines \(d_i\). If we start job i at time \(s(i)\) and finish it at \(f(i) = s(i) + t_i\), the lateness \(l_i = \max(0, f(i)-d_i)\).
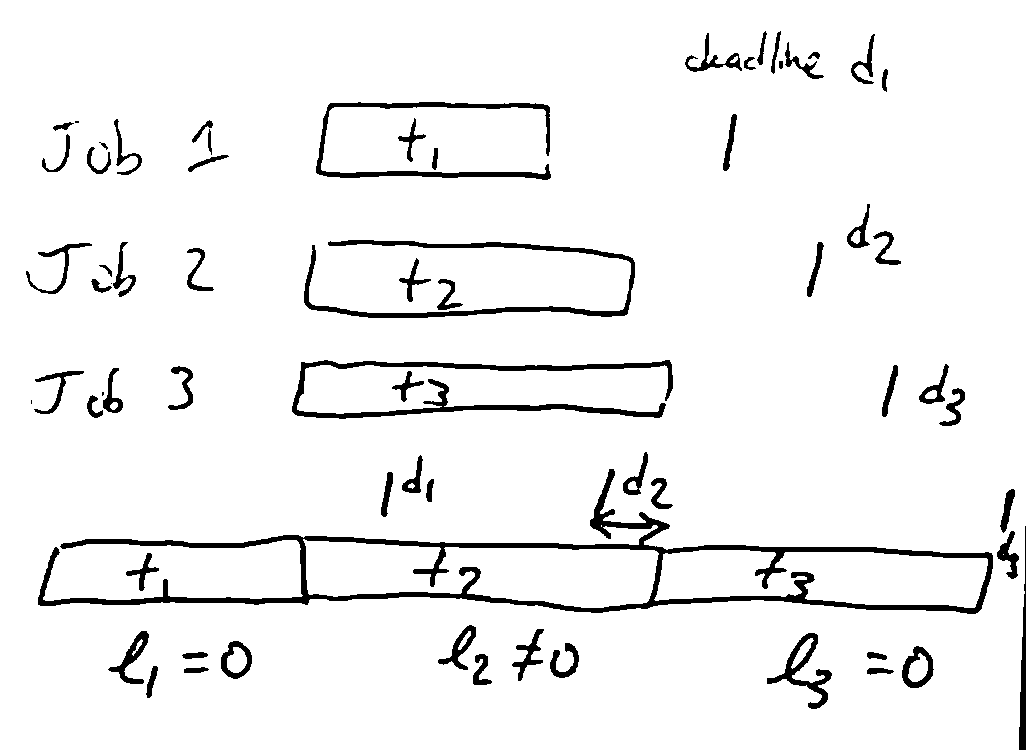
We want a schedule minimizing the maximum lateness \(\max_i l_i\).
A greedy strategy which is optimal: “earliest deadline first”: sort jobs in order of increasing \(d_i\) and execute them in that order.
We use the exchange argument to prove optimality: convert an optimal schedule into the EDF schedule without increasing the maximum lateness.
Note
The EDF schedule has no gaps (idle time) between jobs.
Lemma: There is an optimal schedule with no idle time.
Note
Our EDF schedule also has no inversions: executing job i before j when \(d_i>d_j\).
Lemma: The EDF schedule is the unique idle-free schedule with no inversions, up to rearranging jobs with the same deadline (and note that such rearranging does not change the maximum lateness).
Now the idea is to take an idle-free optimal schedule, and eliminate inversions without increasing max lateness - this will then show EDF is just as good, by above lemma.
Note
Lemma: If an idle-free schedule has an inversion, it has an inversion of adjacent jobs.
Proof: Assume not. Let \((i, j)\) be a closest inversion, and let k be the job after i.
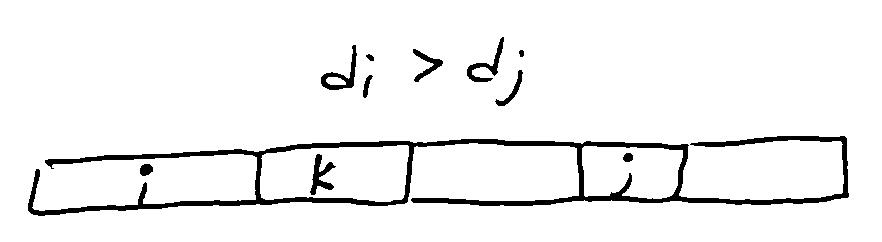
If \(d_i > d_k\), then \((i, k)\) is an adjacent inversion. (done)
Otherwise, \(d_i \leq d_k\), so \(d_k > d_j\), so \((k, j)\) is an inversion. This contradicts \((i, j)\) being a closest inversion.
Note
Lemma: Swapping the jobs of an adjacent inversion reduces the number of inversions by 1, and does not increase the maximum lateness.
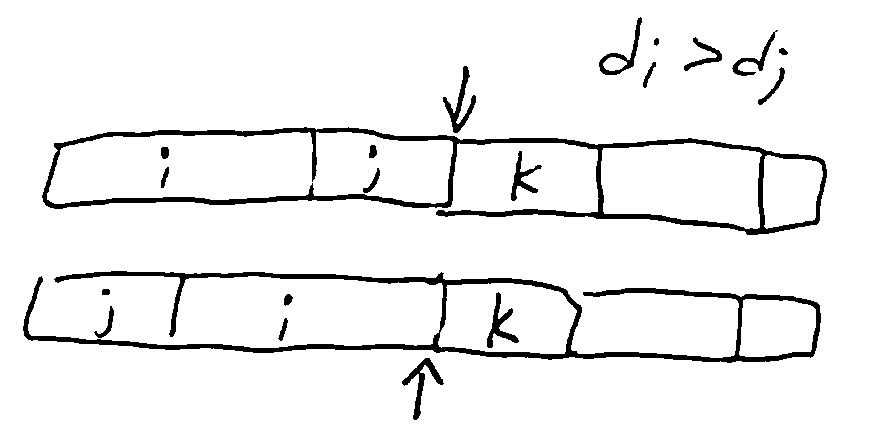
Proof: Swapping i and j doesn’t change the lateness of any jobs other than i and j. Job j can only get a reduced lateness since it now ends earlier. If job i is late,
So the old maximum lateness ≥ the new maximum lateness.
Thm: The EDF schedule is optimal.
Proof: Let \(S\) be an optimal idle-free schedule with fewest inversions.
If it has no inversions, its maximum lateness = that of the EDF schedule.
Otherwise, we can exchange the jobs in an adjacent inversion to get a schedule with fewer inversions, but as good maximum lateness. This contradicts the idea that S has fewest inversions.
Huffman Coding¶
If you want to compress data, you take advantage of the data not being completely random.
Note
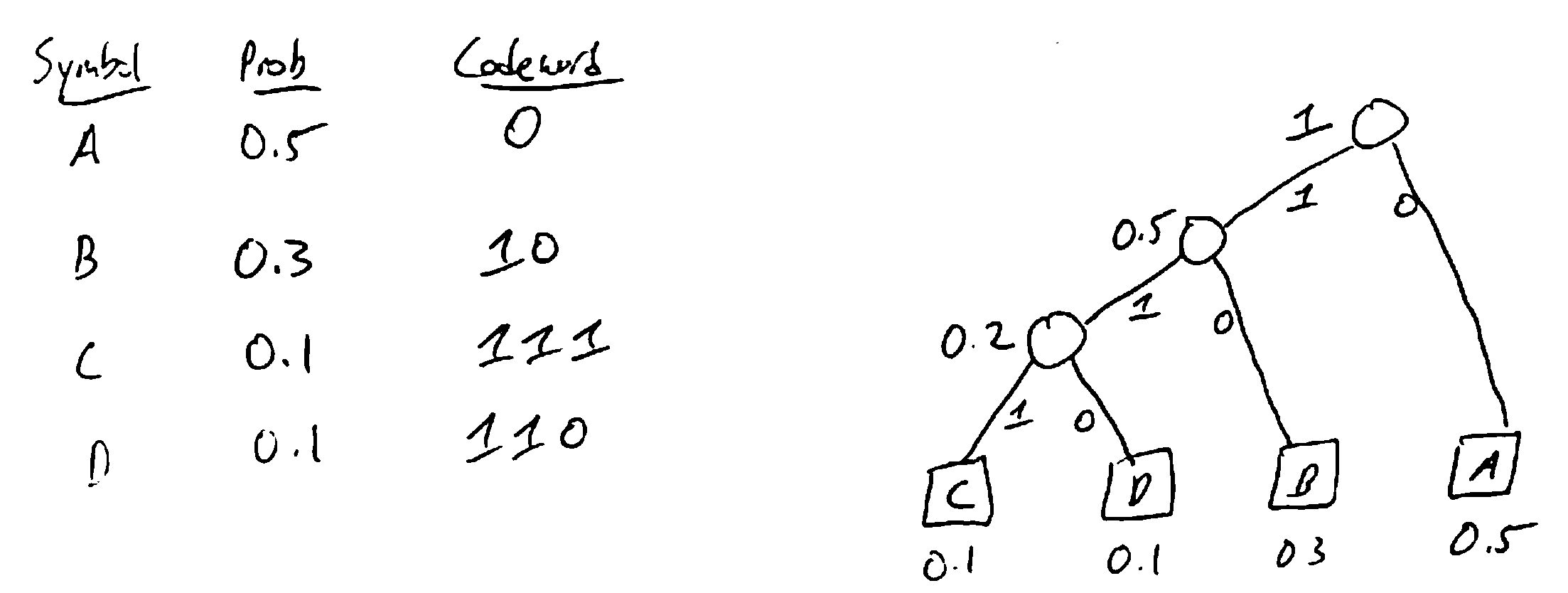
Ex: Suppose you want to send a message using only letters A, B, C, D. In general, would take 2 bits per letter
(e.g. A = 00. B = 01, C = 10, D = 11).
If some letters are more likely than others, could give those shorter codewords. E.g. A = 0, B = 10,
C = 111, D = 100. E.g. CAAB = 1110010 = 7 bits
To be able to uniquely decode, need a prefix-free code: no codeword is a prefix of another.
Huffman coding gives an optimal prefix-free code (i.e. minimizes the expected length of the message).
Greedy algorithm to build encoding/decoding tree: repeatedly merge the nodes with least probability